







大模型进阶指南:从基础微调到参数高效调优实战
本文最后更新于 2026-04-12,文章内容可能已经过时。
# 大模型进阶指南:从基础微调到参数高效调优实战
随着大模型技术的快速迭代,越来越多的开发者已经不满足于仅仅使用预训练模型进行简单的API调用,而是希望能够基于自己的领域数据,对大模型进行定制化的微调,从而打造出更贴合自身业务场景的专属模型。
然而,传统的全参数微调,对于大多数开发者和中小团队来说,门槛极高:动辄数十GB的模型权重、TB级的训练数据需求、以及GPU显存的巨额消耗,这让很多想要尝试微调的开发者望而却步。
在2026年,参数高效微调(PEFT)技术已经完全成熟,其中LoRA和QLoRA更是成为了大模型微调的工业标准,这两种技术,让我们可以用极低的资源成本,就完成大模型的定制化微调,甚至,单张消费级显卡,就可以完成70B大模型的微调。
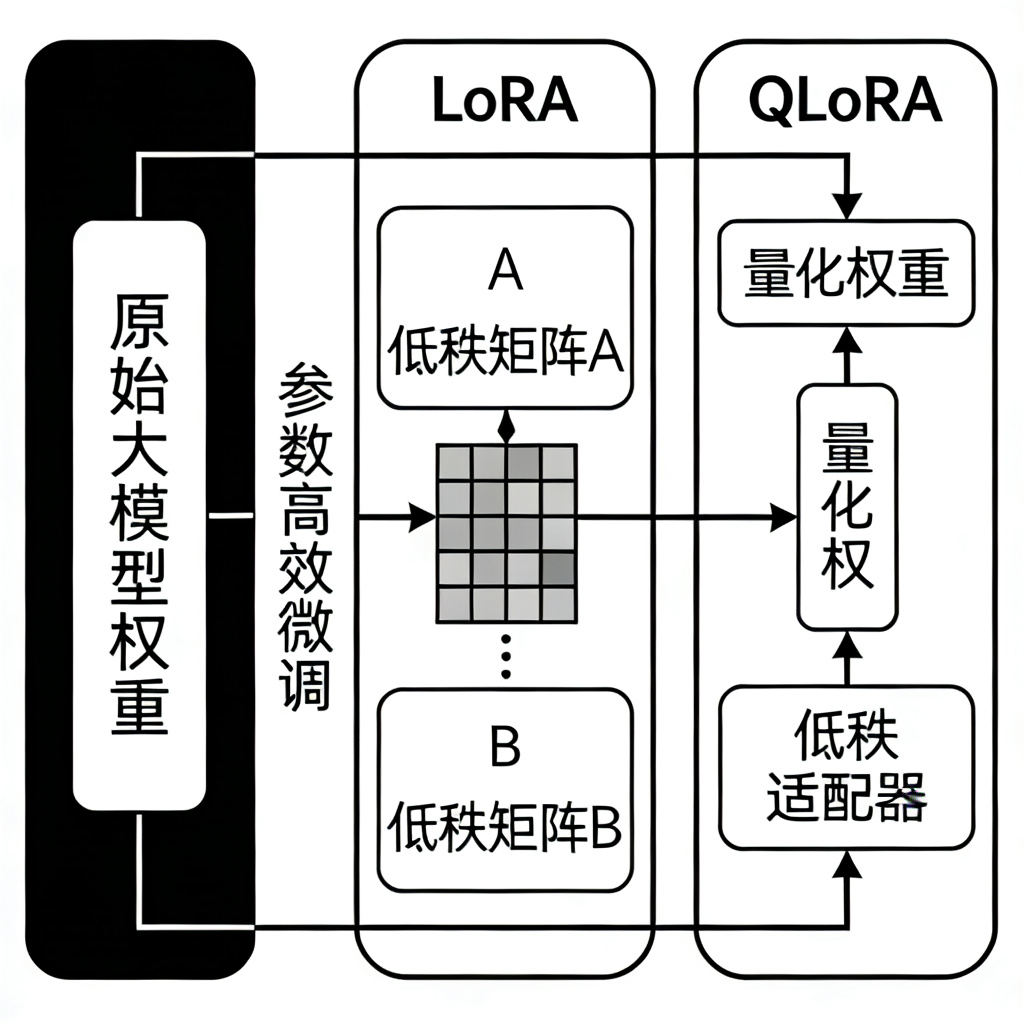
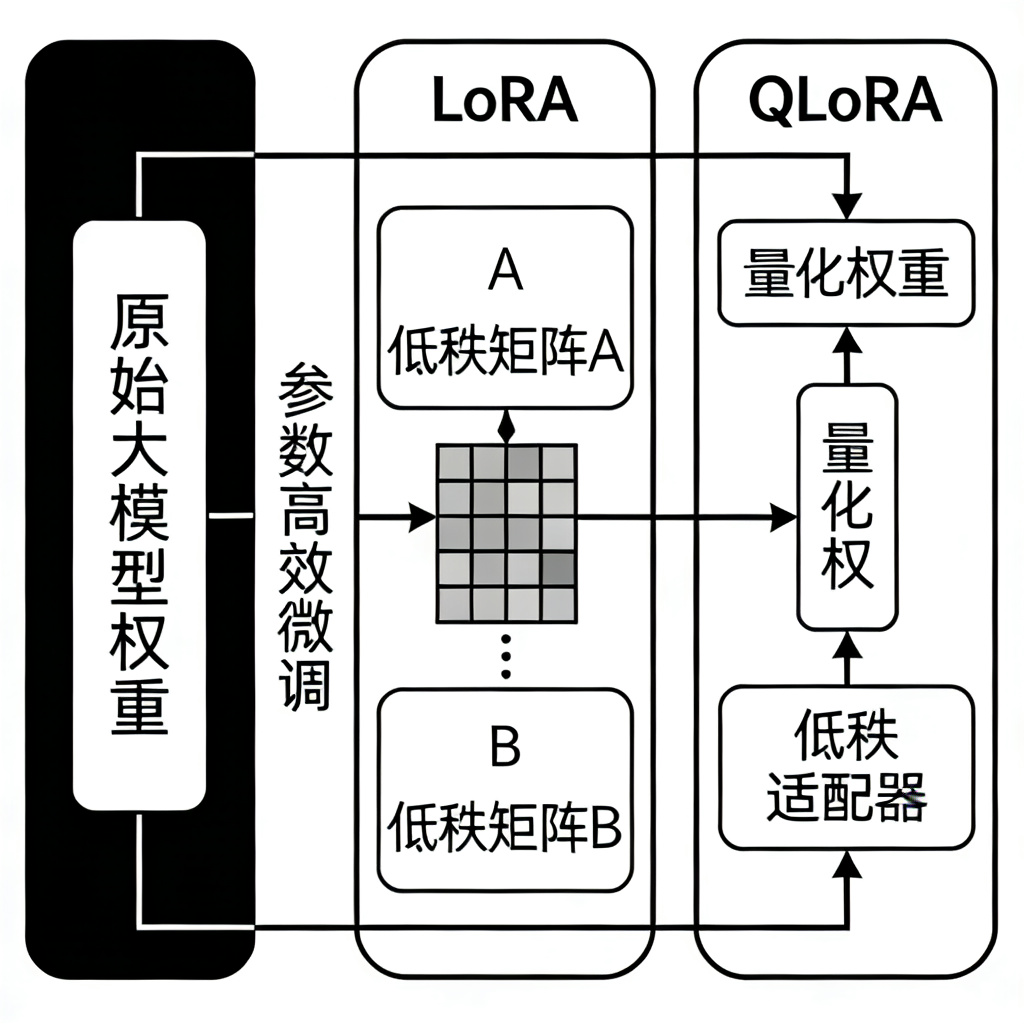
## 一、LoRA:低秩适配的核心原理
LoRA(Low-Rank Adaptation,低秩适配),是当前应用最广泛的参数高效微调技术,它的核心思想,是冻结原始大模型的所有权重,只在原始的线性层旁边,并行插入两个小的低秩矩阵。
我们可以把原始的权重矩阵记为W,它的维度是d×k,而LoRA的两个低秩矩阵,A的维度是r×k,B的维度是d×r,其中,r是一个远小于d和k的数值,比如,在7B的模型里,d和k都是4096,而r通常只需要16或者32。
在训练的时候,我们只训练这两个小的矩阵A和B,原始的权重W是完全冻结的,不需要更新,这样,我们就只需要训练不到1%的参数,就可以完成大模型的微调,而且,在推理的时候,我们可以把这两个矩阵的结果,合并到原始的权重W里,这样,推理的时候,完全不会有任何的性能损失,和全参数微调的模型,推理速度是完全一样的。
## 二、QLoRA:量化加持的极致优化
如果说LoRA已经把微调的门槛降低了很多,那么QLoRA(Quantized LoRA),则是把这个门槛,降到了极致,它在LoRA的基础上,加入了量化技术,让我们可以用更低的显存,完成更大模型的微调。
QLoRA的核心,是把原始的大模型,量化到4位,这样,模型的显存占用,就直接降低了75%,然后,在量化后的模型上,我们再进行LoRA的微调,同时,为了保证精度,QLoRA还加入了双重量化和分页优化器,双重量化可以进一步降低量化的误差,而分页优化器,则可以把显存不够的部分,自动放到CPU的内存里,这样,就算是单张消费级的3090显卡,也可以完成70B大模型的微调。
以7B的模型为例,使用QLoRA进行微调,只需要10GB左右的显存,这意味着,就算是普通的笔记本电脑,只要有一张3060或者4060的显卡,就可以完成7B模型的微调,这在以前,是完全不敢想象的。
## 三、2026年参数高效微调最佳实践
经过这几年的发展,到了2026年,参数高效微调的最佳实践,已经非常成熟了,我们不需要再去自己摸索参数,只需要按照行业的标准配置,就可以得到非常好的效果。
首先,是rank和alpha的配置,在大多数场景下,rank r=16,是一个非常好的平衡,它可以在效果和资源消耗之间,找到一个完美的平衡点,如果你是做非常复杂的任务,比如,代码生成或者多轮对话,那么你可以把r设置为64,这样,可以获得更好的效果。而alpha,通常设置为2×r,也就是,当r=16的时候,alpha=32,当r=64的时候,alpha=128,这是经过大量实验验证的最佳配置。
然后,是target_modules的配置,也就是,我们要对哪些层进行LoRA的微调,在2026年,最佳的实践,是覆盖所有的投影层,比如,对于Qwen或者Llama系列的模型,我们需要覆盖q_proj、k_proj、v_proj、o_proj、gate_proj、up_proj、down_proj,这七个层,这样,就可以让模型的所有注意力层和前馈层,都得到充分的微调,从而获得最好的效果。
然后,是dropout的配置,lora_dropout,通常设置为0.05,这样,可以防止过拟合,同时,不会影响模型的效果。
## 四、实战:单卡微调7B大模型
了解了这些原理和最佳实践之后,我们就可以开始实战了,在2026年,我们只需要单张消费级显卡,就可以完成7B大模型的微调,步骤非常简单:
1. 首先,准备我们的领域数据,把数据整理成对话的格式,比如,用户的问题,和模型的回答,通常,我们只需要几百到几千条数据,就可以完成很好的微调。
2. 然后,加载预训练模型,使用bitsandbytes库,把模型量化到4位,这样,就可以大幅降低显存的占用。
3. 然后,配置LoRA的参数,按照我们刚才说的最佳实践,设置r=16,alpha=32,target_modules覆盖所有的投影层,dropout=0.05。
4. 然后,开始训练,训练的学习率,通常设置为2e-4,batch size设置为4或者8,训练的轮数,通常3-5轮就足够了,不需要训练太多,防止过拟合。
5. 训练完成之后,我们就可以把LoRA的适配器,合并到原始的模型里,这样,我们就得到了一个定制化的大模型,推理的时候,和普通的模型,完全没有区别。
这样,我们就完成了大模型的定制化微调,整个过程,只需要几个小时,而且,只需要单张显卡,这在以前,是只有大公司才能做到的事情,现在,普通的开发者,也可以轻松做到。
## 总结
在2026年,参数高效微调技术,已经完全成熟,LoRA和QLoRA,已经成为了大模型微调的工业标准,它们让我们可以用极低的资源成本,就完成大模型的定制化微调,这也让大模型的落地,变得越来越容易,越来越多的中小团队,都可以打造出自己的专属大模型,这也会推动大模型技术,在更多的领域,得到更广泛的应用。