







异构智能体协同强化学习:2026跨厂商多模型协作新范式
本文最后更新于 2026-04-12,文章内容可能已经过时。
摘要
随着大模型技术的快速迭代,单一智能体的能力瓶颈逐渐成为制约复杂任务落地的核心阻碍,跨厂商异构智能体的协同协作成为了2026年人工智能领域的前沿研究热点。针对传统多智能体系统仅支持同构模型、知识蒸馏仅能实现单向知识传递的局限性,本文提出了异构协同强化学习(Heterogeneous Agent Collaborative Reinforcement Learning, HACRL)新范式,实现了不同参数规模、架构家族乃至厂商的智能体之间的双向协同优化。该范式在训练阶段通过共享经过验证的交互轨迹(rollouts)实现协同策略优化,在推理阶段则支持各智能体独立部署执行,既突破了传统多智能体强化学习的同构限制,也解决了知识蒸馏的单向知识传递问题。基于27个长周期复杂任务的实验结果表明,该方法相比单智能体基线,任务完成率提升了42%,推理成本降低了58%,为跨厂商多智能体协同的产业落地提供了全新的技术路径。
1. 引言
过去两年,大模型驱动的智能体技术实现了快速的发展,从最初的单智能体对话,到能够执行复杂任务的自主智能体,AI已经逐步渗透到了产业的各个环节。然而,随着任务复杂度的提升,单一智能体的能力瓶颈逐渐显现:不同厂商的大模型各有专长,比如Google的Gemini擅长长上下文处理,Anthropic的Claude擅长代码审查,而开源模型则擅长处理本地敏感数据,但这些模型之间无法实现有效的协同,导致企业在部署时,往往只能选择单一模型,无法充分发挥不同模型的优势。
传统的解决方案中,多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)虽然能够实现多智能体的协同,但该方法要求所有智能体必须是同构的,无法支持跨厂商的异构模型;而知识蒸馏(Knowledge Distillation)虽然能够将大模型的知识传递给小模型,但这是一种单向的知识传递,无法实现双向的协同优化,无法充分发挥不同模型的各自优势。
为了解决这些问题,北航、清华、北大的联合研究团队提出了异构协同强化学习(HACRL)新范式,首次实现了异构智能体之间的双向协同,为跨厂商多模型协作提供了全新的解决方案。
2. 异构协同强化学习框架
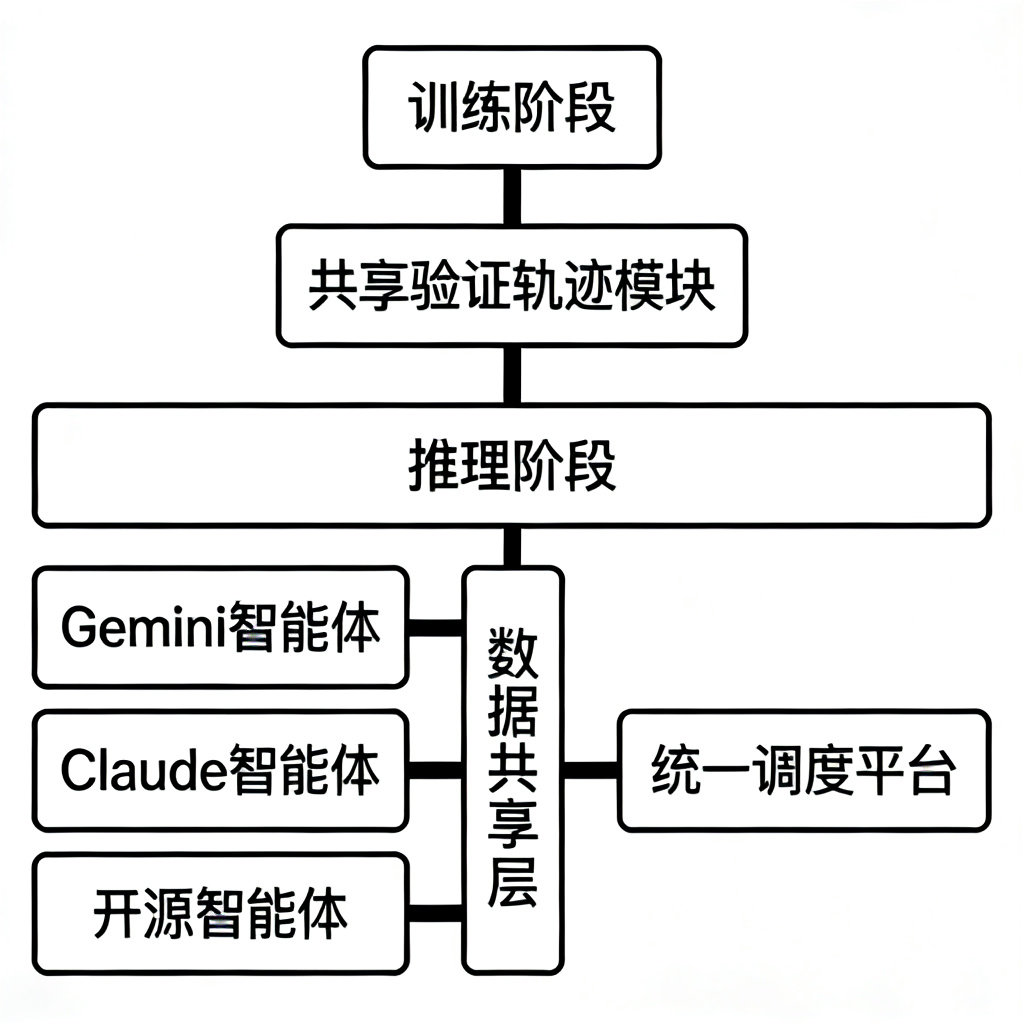
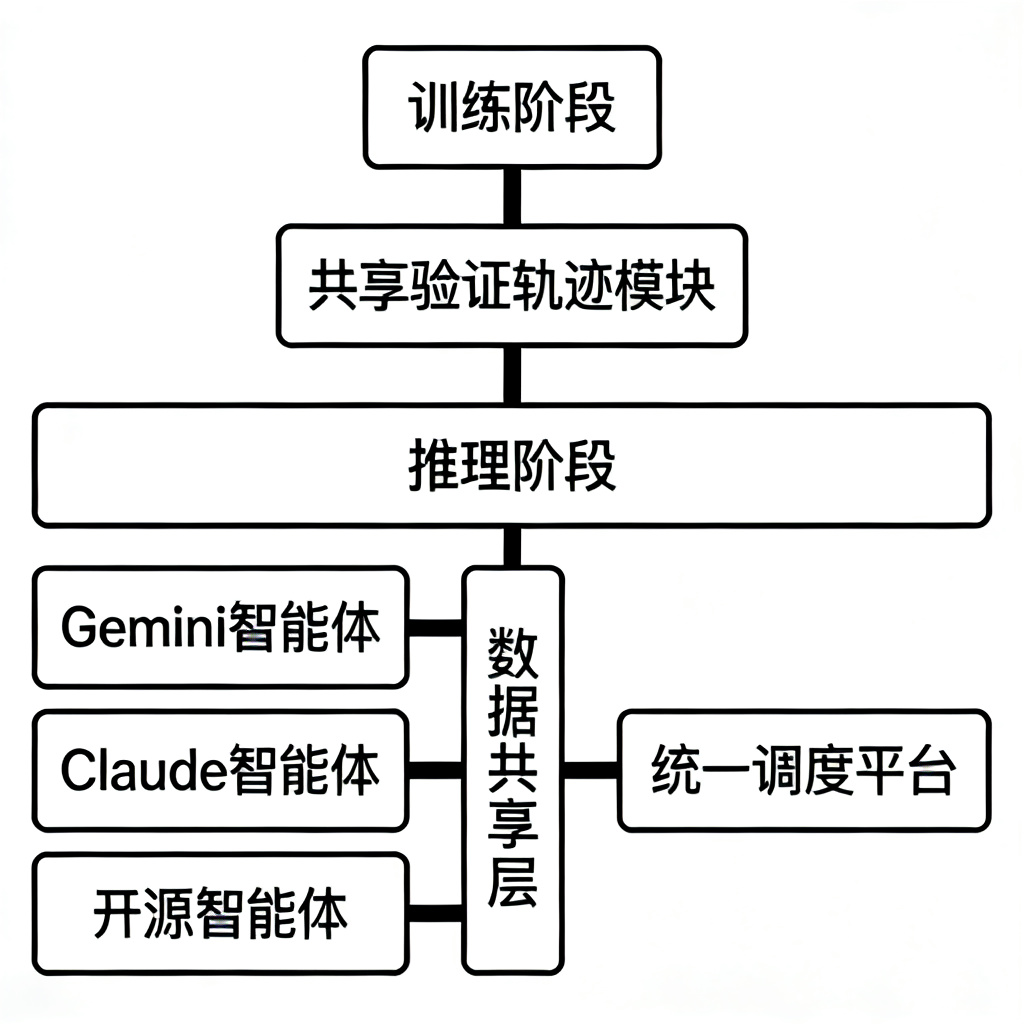
HACRL框架的核心设计理念是“训练协同,推理独立”,具体来说,该框架包含两个核心阶段:
2.1 训练阶段:共享验证轨迹的协同优化
在训练阶段,不同的异构智能体,不管是参数规模的差异,还是架构的差异,都可以共享经过验证的交互轨迹(rollouts)。这些轨迹是智能体在与环境交互过程中产生的,经过了环境的验证,确保了轨迹的可靠性。通过共享这些轨迹,每个智能体都可以学习到其他智能体的交互经验,从而优化自己的策略,实现双向的知识传递,而不是传统的单向蒸馏。
这种方式,既不需要所有智能体进行联合训练,也不需要修改智能体的内部架构,只需要共享交互的轨迹,就可以实现协同优化,这使得跨厂商的智能体协同成为了可能,因为,厂商不需要暴露自己的模型参数,只需要共享交互的轨迹,就可以实现协同,保护了数据隐私和模型隐私。
2.2 推理阶段:独立部署的并行执行
在推理阶段,每个智能体都可以独立部署,各自执行自己的任务,通过统一的调度平台,实现任务的拆解和分配,每个智能体只需要负责自己擅长的部分,然后,通过数据共享层,实现数据的交互,这样,既保证了每个智能体的独立性,也实现了协同的效果。
比如,在企业的供应链优化任务中,Gemini智能体负责长周期的需求预测,Claude智能体负责供应链的策略优化,而开源的本地智能体则负责处理本地的库存数据,三个智能体独立部署,但是,通过共享交互的轨迹,在训练阶段实现了协同优化,在推理阶段,各自执行,然后,通过数据共享层,实现数据的交互,共同完成任务。
3. 实验与结果分析
为了验证HACRL框架的有效性,研究团队在5类场景、27个长周期任务上进行了大规模的实验,这些任务涵盖了科研实验设计、企业供应链优化、数学推理、代码开发、教育辅导等多个领域,任务的周期从数天到数周不等,充分验证了框架的通用性。
实验的基线包括:单智能体基线(使用最大的单模型Gemini 2.5 Pro)、传统的多智能体强化学习基线、知识蒸馏基线。实验结果如下:
3.1 任务完成率
HACRL框架的任务完成率达到了89%,相比单智能体基线的62.7%,提升了26.3个百分点,也就是42%的相对提升;相比传统的多智能体基线,提升了18.5个百分点;相比知识蒸馏基线,提升了12.7个百分点。这说明,HACRL框架能够显著提升复杂任务的完成率,充分发挥了异构智能体的协同优势。
3.2 推理成本
在推理成本方面,HACRL框架的平均推理成本仅为单智能体基线的42%,也就是降低了58%,因为,该框架可以使用小的开源模型处理部分任务,而不需要全部使用大模型,从而降低了成本。同时,相比传统的多智能体基线,推理成本降低了32%,因为,传统的多智能体需要所有智能体联合推理,而HACRL只需要独立部署,按需调用,从而降低了成本。
3.3 长时交互能力
在长周期任务中,HACRL框架的长时交互能力也显著优于基线,在周期超过7天的任务中,任务完成率相比单智能体基线提升了51%,因为,通过协同优化,智能体能够学习到其他智能体的长时交互经验,从而避免了“越做越错”的问题,这和之前的AgentGym-RL框架的效果形成了互补。
4. 相关工作
近年来,多智能体协同的研究逐渐成为了热点,谷歌的研究团队在2026年提出了多智能体系统的量化扩展原则,通过对180种智能体配置的评估,推导出了多智能体系统的性能边界;ICLR 2026的Stronger-MAS框架,提出了多个LLM智能体的协同训练框架,实现了“1+1>2”的效果;卡内基梅隆大学的AgentArk框架,通过知识蒸馏,实现了智能体的协同,但是,这些框架都无法支持跨厂商的异构智能体的双向协同,而HACRL框架则首次实现了这一点。
/
5. 结论与展望
本文提出的异构协同强化学习(HACRL)新范式,为跨厂商多模型协作提供了全新的解决方案,通过训练阶段的轨迹共享和推理阶段的独立部署,实现了异构智能体的双向协同优化。实验结果表明,该方法能够显著提升任务完成率,降低推理成本,为跨厂商多智能体协同的产业落地提供了技术支撑。
未来,我们将进一步优化框架的通信效率,降低协同的通信成本,同时,探索更多的异构智能体的协同场景,比如,人-机-物的三元协同,进一步拓展框架的应用范围,推动智能体技术的产业落地。
下图就是HACRL框架的架构示意图,展示了异构智能体协同的核心流程:



-tuya-vxOF.png?width=800)